Latest DP-700 Test Pass4sure, DP-700 Reliable Dumps Ebook
Wiki Article
BONUS!!! Download part of Pass4SureQuiz DP-700 dumps for free: https://drive.google.com/open?id=16B00pZ_G67X8KLs0IWJz6uaP5eafZLBk
The number of questions of the DP-700 study materials you have done has a great influence on your passing rate. As for our study materials, we have prepared abundant exercises for you to do. You can take part in the real DP-700 exam after you have memorized all questions and answers accurately. Also, we just pick out the most important knowledge to learn. Through large numbers of practices, you will soon master the core knowledge of the DP-700 Exam. It is important to review the questions you always choose mistakenly. You should concentrate on finishing all exercises once you are determined to pass the DP-700 exam.
Microsoft DP-700 Exam copyright Topics:
| Topic | Details |
|---|---|
| Topic 1 |
|
| Topic 2 |
|
| Topic 3 |
|
>> Latest DP-700 Test Pass4sure <<
Pass Guaranteed 2026 DP-700: Implementing Data Engineering Solutions Using Microsoft Fabric –Professional Latest Test Pass4sure
We will have a dedicated specialist to check if our DP-700 learning materials are updated daily. We can guarantee that our DP-700 exam question will keep up with the changes by updating the system, and we will do our best to help our customers obtain the latest information on learning materials to meet their needs. If you choose to purchase our DP-700 quiz torrent, you will have the right to get the update system and the update system is free of charge. We do not charge any additional fees. Once our DP-700 Learning Materials are updated, we will automatically send you the latest information about our DP-700 exam question. We assure you that our company will provide customers with a sustainable update system.
Microsoft Implementing Data Engineering Solutions Using Microsoft Fabric Sample Questions (Q23-Q28):
NEW QUESTION # 23
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a KQL database that contains two tables named Stream and Reference. Stream contains streaming data in the following format.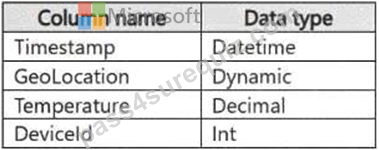
Reference contains reference data in the following format.
Both tables contain millions of rows.
You have the following KQL queryset.
You need to reduce how long it takes to run the KQL queryset.
Solution: You change the join type to kind=outer.
Does this meet the goal?
- A. Yes
- B. No
Answer: B
Explanation:
An outer join will include unmatched rows from both tables, increasing the dataset size and processing time.
It does not improve query performance.
NEW QUESTION # 24
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a KQL database that contains two tables named Stream and Reference. Stream contains streaming data in the following format.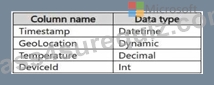
Reference contains reference data in the following format.
Both tables contain millions of rows.
You have the following KQL queryset.
You need to reduce how long it takes to run the KQL queryset.
Solution: You move the filter to line 02.
Does this meet the goal?
- A. Yes
- B. No
Answer: A
Explanation:
Moving the filter to line 02: Filtering the Stream table before performing the join operation reduces the number of rows that need to be processed during the join. This is an effective optimization technique for queries involving large datasets.
NEW QUESTION # 25
You have a Fabric workspace named Workspace1 that contains the items shown in the following table.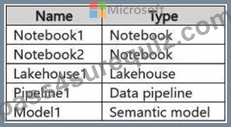
For Model1, the Keep your Direct Lake data up to date option is disabled.
You need to configure the execution of the items to meet the following requirements:
How should you orchestrate each item? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.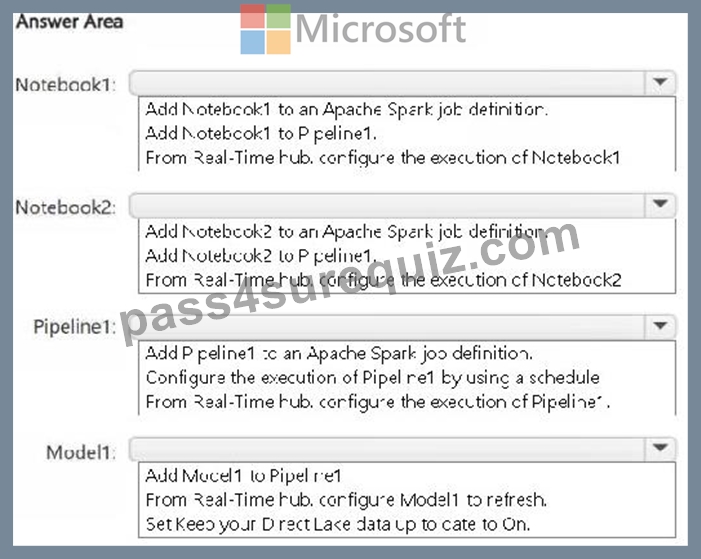
Answer:
Explanation: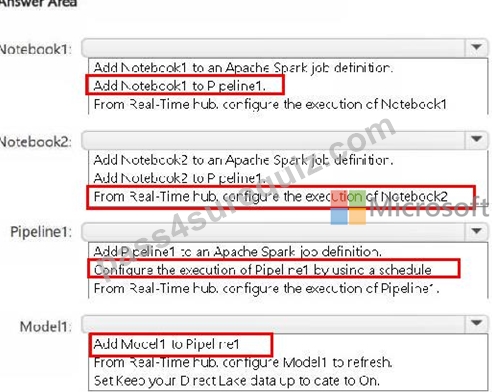
NEW QUESTION # 26
You have an Azure Data Lake Storage Gen2 account named storage1 and an Amazon S3 bucket named storage2.
You have the Delta Parquet files shown in the following table.
You have a Fabric workspace named Workspace1 that has the cache for shortcuts enabled. Workspace1 contains a lakehouse named Lakehouse1. Lakehouse1 has the following shortcuts:
A shortcut to ProductFile aliased as Products
A shortcut to StoreFile aliased as Stores
A shortcut to TripsFile aliased as Trips
The data from which shortcuts will be retrieved from the cache?
- A. Stores only
- B. Products. Stores, and Trips
- C. Trips and Stores only
- D. Products only
- E. Products and Store only
Answer: E
Explanation:
When the cache for shortcuts is enabled in Fabric, the data retrieval is governed by the caching behavior, which generally retains data for a specific period after it was last accessed. The data from the shortcuts will be retrieved from the cache if the data is stored in locations that support caching. Here's a breakdown based on the data's location:
Products: The ProductFile is stored in Azure Data Lake Storage Gen2 (storage1). Since Azure Data Lake is a supported storage system in Fabric and the file is relatively small (50 MB), this data is most likely cached and can be retrieved from the cache.
Stores: The StoreFile is stored in Amazon S3 (storage2), and even though it is stored in a different cloud provider, Fabric can cache data from Amazon S3 if caching is enabled. This data (25 MB) is likely cached and retrievable.
Trips: The TripsFile is stored in Amazon S3 (storage2) and is significantly larger (2 GB) compared to the other files. While Fabric can cache data from Amazon S3, the larger size of the file (2 GB) may exceed typical cache sizes or retention windows, causing this file to likely be retrieved directly from the source instead of the cache.
NEW QUESTION # 27
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Fabric eventstream that loads data into a table named Bike_Location in a KQL database. The table contains the following columns:
BikepointID
Street
Neighbourhood
No_Bikes
No_Empty_Docks
Timestamp
You need to apply transformation and filter logic to prepare the data for consumption. The solution must return data for a neighbourhood named Sands End when No_Bikes is at least 15. The results must be ordered by No_Bikes in ascending order.
Solution: You use the following code segment:
Does this meet the goal?
- A. Yes
- B. no
Answer: B
Explanation:
This code does not meet the goal because it uses sort by without specifying the order, which defaults to ascending, but explicitly mentioning asc improves clarity.
Correct code should look like:
NEW QUESTION # 28
......
Some of our customers are white-collar workers with no time to waste, and need a Microsoft certification urgently to get their promotions, meanwhile the other customers might aim at improving their skills. So we try to meet different requirements by setting different versions of our DP-700 question and answers. The special one is online DP-700 engine version. As an online tool, it is convenient and easy to study, supports all Web Browsers and system including Windows, Mac, Android, iOS and so on. You can apply this version of DP-700 exam questions on all eletric devices.
DP-700 Reliable Dumps Ebook: https://www.pass4surequiz.com/DP-700-exam-quiz.html
- Microsoft DP-700 Questions To Complete Your Preparation [2026] ???? Open ➽ www.examcollectionpass.com ???? and search for ✔ DP-700 ️✔️ to download exam materials for free ????Test DP-700 Dates
- Pdfvce Microsoft DP-700 Desktop Practice Exam ???? Download 【 DP-700 】 for free by simply entering { www.pdfvce.com } website ????Trustworthy DP-700 Exam Torrent
- Sample DP-700 Questions ???? Trustworthy DP-700 Exam Torrent ???? Upgrade DP-700 Dumps ???? Search for 「 DP-700 」 and obtain a free download on 「 www.validtorrent.com 」 ????PDF DP-700 Cram Exam
- Pdfvce Microsoft DP-700 Desktop Practice Exam ???? Search for ▷ DP-700 ◁ and download it for free on [ www.pdfvce.com ] website ????New DP-700 Dumps Free
- New DP-700 Dumps Free ???? Valid copyright DP-700 Ebook ???? PDF DP-700 Cram Exam ???? Search for 《 DP-700 》 and download exam materials for free through ⮆ www.troytecdumps.com ⮄ ????Trustworthy DP-700 Exam Torrent
- 100% Pass DP-700 - Useful Latest Implementing Data Engineering Solutions Using Microsoft Fabric Test Pass4sure ???? ⮆ www.pdfvce.com ⮄ is best website to obtain ▛ DP-700 ▟ for free download ????DP-700 Valid Mock Exam
- Useful Latest DP-700 Test Pass4sure Provide Prefect Assistance in DP-700 Preparation ???? Go to website [ www.prepawaypdf.com ] open and search for “ DP-700 ” to download for free ????Sample DP-700 Questions
- Pdfvce Microsoft DP-700 Desktop Practice Exam ???? Open ➥ www.pdfvce.com ???? enter ▶ DP-700 ◀ and obtain a free download ????Upgrade DP-700 Dumps
- Trustworthy DP-700 Exam Torrent ???? Latest DP-700 Mock Test ???? Latest DP-700 Mock Test ???? Open ▷ www.troytecdumps.com ◁ and search for 《 DP-700 》 to download exam materials for free ????New DP-700 Dumps Free
- 100% Pass DP-700 - Useful Latest Implementing Data Engineering Solutions Using Microsoft Fabric Test Pass4sure ???? Search for ▷ DP-700 ◁ and download it for free on ⮆ www.pdfvce.com ⮄ website ⚽Upgrade DP-700 Dumps
- Valid copyright DP-700 Ebook ⛵ New DP-700 Dumps Free ❔ Valid copyright DP-700 Ebook ???? 《 www.torrentvce.com 》 is best website to obtain “ DP-700 ” for free download ????DP-700 New Exam Bootcamp
- jaydkuk633029.laowaiblog.com, reganzqjq602256.wikiexcerpt.com, aprilaulh433306.newsbloger.com, kaitlynxbzu522769.blogsidea.com, lancecnum092999.muzwiki.com, cormacxpfi648376.dailyblogzz.com, tiannapcvo840462.tkzblog.com, lilliztac798315.tokka-blog.com, keiranacai352267.wikinarration.com, bookmarkyourpage.com, Disposable vapes
2026 Latest Pass4SureQuiz DP-700 copyright and DP-700 copyright Free Share: https://drive.google.com/open?id=16B00pZ_G67X8KLs0IWJz6uaP5eafZLBk
Report this wiki page